


{kind=link}
{kind=link}
The Conversation (0)
Artificial Intelligence

Building Ethical Machine Learning Systems
Learn how ethical machine learning systems use fairness, transparency, oversight, and balanced data to build more responsible and trustworthy AI models.
You know what machine learning is in technical terms; it’s all about systems picking up on patterns from data to make predictions. But the real challenge is figuring out if those predictions are fair and transparent for everyone involved.
Machine learning models are now at the foundation of hiring, lending, healthcare, and content moderation. Cases you see in machine learning news today demonstrate what happens when bias is unchecked. If you build AI systems or work with machine learning development services, ethics must guide data choices, evaluation metrics, and deployment rules from the start.
Ethics in AI is not abstract. It translates into design choices you make at each stage of development. If you build models that affect real people, you need clear principles:
These are not marketing terms. They shape practical decisions like feature selection, dataset design, and evaluation strategy.
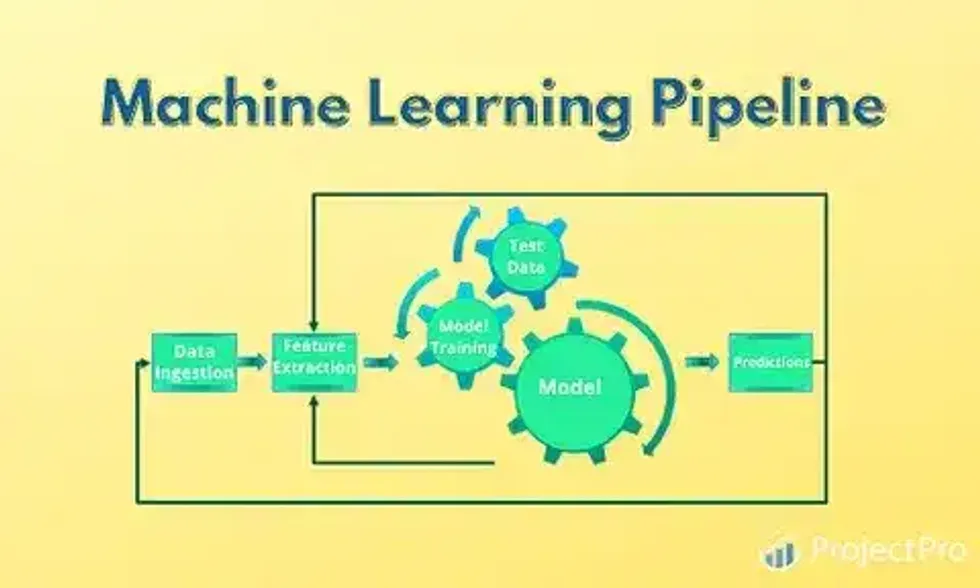 What is ML pipeline? What is ML pipeline?
What is ML pipeline? What is ML pipeline?
Bias can enter at multiple stages of development, often before model tuning:
Ethical outcomes do not appear automatically. They must be defined before machine learning model training begins. If fairness is not measurable, it will not be optimized.
Start by translating principles into measurable metrics, such as equal false positive rates across demographic groups, similar precision and recall across subgroups, and a maximum allowed disparity threshold.
Without clear numeric targets, teams usually optimize overall accuracy. Accuracy alone can hide unfair outcomes affecting specific groups.
Ethics affects roles like data scientists, product managers, lawyers, compliance officers, and management. The teams must agree upon acceptable risk levels, sensitive attributes to track, and documentation best practices. In case management is more focused on speed than fairness, ethical objectives are unlikely to be achieved.
Every model has boundaries. Write them down:
Clear ethical objectives guide later decisions.
 Data Data
Data Data
If your data is biased, your model is biased. Do a structured audit before training your model.
Divide your data into groups by gender, age, ethnicity (if allowed by law), region, and income. Underrepresentation causes high error rates for those groups.
Bias does not always come from obvious attributes. Proxy features may indirectly encode sensitive information. Examples:
If removing a sensitive attribute does not change outcomes, examine correlated features.
Often-used techniques include re-sampling methods such as oversampling minority classes or undersampling majority classes, re-weighting methods such as assigning higher loss weight to underrepresented classes, and data augmentation techniques to synthesize data to improve coverage. These techniques all have trade-offs. Oversampling can lead to overfitting, while undersampling may result in data being discarded.
When your data is balanced, recalculate your subgroup metrics, compare false positives and false negatives, and note any changes in disparity. Repeat data audits when you add new data, expand into new markets, or modify your labeling rules. Bias can creep into your data through gradual changes.
Accuracy is not enough. If you can't explain your decision, you can't defend your decision to users, regulators, or your own team.
Some systems may involve higher stakes, such as credit scoring, hiring tools, healthcare diagnostics, and insurance underwriting. In these situations, simpler methods are preferred, such as logistic regression, decision trees, and rule-based systems. These methods may trade some accuracy for interpretability.
If complex models are necessary, use tools that reveal decision logic:
For example, if a loan application is rejected, the system should explain which features contributed most and what changes might lead to approval.
Create artifacts such as:
Model cards should describe training data sources, subgroup performance, weaknesses, and ethical considerations.
 Step 4. Test for Fairness Before Deployment Apple
Step 4. Test for Fairness Before Deployment Apple
Break performance metrics down by subgroup rather than relying solely on overall accuracy. Track precision, recall, false positive rate, and false negative rate. Even strong overall accuracy can hide large subgroup gaps.
If outcomes change significantly, investigate the influence of features.
Models often fail in unusual situations. Test scenarios such as:
Document disparity thresholds, testing results, and mitigation steps taken. Fairness testing focuses on identifying and reducing unjust gaps before deployment.
Even well-tested models make mistakes. Ethical systems require human supervision. High-risk decisions that often require review include:
Possible oversight practices include reviewing high-risk decisions, auditing random samples regularly, and escalating borderline cases. Humans must have the authority to override model outputs.
Every system needs ownership. Document:
Teams should also be trained to recognize bias patterns and understand fairness metrics.
Ethical machine learning does not end at launch. Data and user behavior change over time. Monitor metrics such as subgroup accuracy, false-positive and false-negative rates, decision approval rates, and complaint volume. Compare results regularly to identify emerging issues.
Two important types of drift occur:
If drift crosses defined thresholds, trigger a review.
Document:
Continuous monitoring ensures ethical intent becomes an ongoing practice rather than a one-time effort.
To achieve ethical ML models, you need goals, balanced data sets, transparent models, fairness testing, human oversight, and monitoring. These processes decrease risk and increase trust.
If you're building systems that make decisions that matter, then you should consider ethics to be an integral part of your engineering work. This means checking your assumptions, evaluating the impact of subgroups, and monitoring your model's performance over time. Responsible AI does not happen naturally. It's something that happens through a series of conscious decisions along the way.
Guest Writer: Karyna Naminas, CEO of Label Your Data
GearBrain Compatibility Find Engine
A pioneering recommendation platform where you can research,
discover, buy, and learn how to connect and optimize smart devices.
Join our community! Ask and answer questions about smart devices and save yours in My Gear.
